
Now I Really Won That AI Bet
...

In June 2022, I bet a commenter $100 that AI would master image compositionality by June 2025.
DALL-E2 had just come out, showcasing the potential of AI art. But it couldn’t follow complex instructions; its images only matched the “vibe” of the prompt. For example, here were some of its attempts at “a red sphere on a blue cube, with a yellow pyramid on the right, all on top of a green table”.

At the time, I wrote:
I’m not going to make the mistake of saying these problems are inherent to AI art. My guess is a slightly better language model would solve most of them…for all I know, some of the larger image models have already fixed these issues. These are the sorts of problems I expect to go away with a few months of future research.
Commenters objected that this was overly optimistic. AI was just a pattern-matching “stochastic parrot”. It would take a deep understanding of grammar to get a prompt exactly right, and that would require some entirely new paradigm beyond LLMs. For example, from Vitor:
Why are you so confident in this? The inability of systems like DALL-E to understand semantics in ways requiring an actual internal world model strikes me as the very heart of the issue. We can also see this exact failure mode in the language models themselves. They only produce good results when the human asks for something vague with lots of room for interpretation, like poetry or fanciful stories without much internal logic or continuity.
Not to toot my own horn, but two years ago you were naively saying we'd have GPT-like models scaled up several orders of magnitude (100T parameters) right about now (https://slatestarcodex.com/2020/06/10/the-obligatory-gpt-3-post/#comment-912798).
I'm registering my prediction that you're being equally naive now. Truly solving this issue seems AI-complete to me. I'm willing to bet on this (ideas on operationalization welcome).
So we made a bet!
All right. My proposed operationalization of this is that on June 1, 2025, if either if us can get access to the best image generating model at that time (I get to decide which), or convince someone else who has access to help us, we'll give it the following prompts:
1. A stained glass picture of a woman in a library with a raven on her shoulder with a key in its mouth
2. An oil painting of a man in a factory looking at a cat wearing a top hat
3. A digital art picture of a child riding a llama with a bell on its tail through a desert
4. A 3D render of an astronaut in space holding a fox wearing lipstick
5. Pixel art of a farmer in a cathedral holding a red basketball
We generate 10 images for each prompt, just like DALL-E2 does. If at least one of the ten images has the scene correct in every particular on 3/5 prompts, I win, otherwise you do. Loser pays winner $100, and whatever the result is I announce it on the blog (probably an open thread). If we disagree, Gwern is the judge.
Some image models of the time refused to draw humans, so we agreed that robots could stand in for humans in pictures that required them.
In September 2022, I got some good results from Google Imagen and announced I had won the three-year bet in three months. Commenters yelled at me, saying that Imagen still hadn’t gotten them quite right and my victory declaration was premature. The argument blew up enough that Edwin Chen of Surge, an “RLHF and human LLM evaluation platform”, stepped in and asked his professional AI data labelling team. Their verdict was clear: the AI was bad and I was wrong. Rather than embarrass myself further, I agreed to wait out the full length of the bet and re-evaluate in June 2025.
The bet is now over, and official judge Gwern agrees I’ve won. Before I gloat, let’s look at the images that got us here.
AI Compositionality: A Three Year Retrospective
Image Set 1: June 2022
When we first made the bet in June 2022, the best that an AI model could do on the five prompts was:

You can see why people would be skeptical! In most images, the pieces are all there: astronauts, foxes, lipstick. But they’re combined in whatever way seems most “plausible” or “realistic”, rather than the way indicated by the prompt - so for example, the astronaut is wearing the lipstick, rather than the fox. Other times there are unrelated inexplicable failures, like the half-fox, half-astronaut abomination in panel #1. Here we get 0/5.
Image Set 2: September 2022
Three months later, I declared premature victory when Google Imagen produced the following:
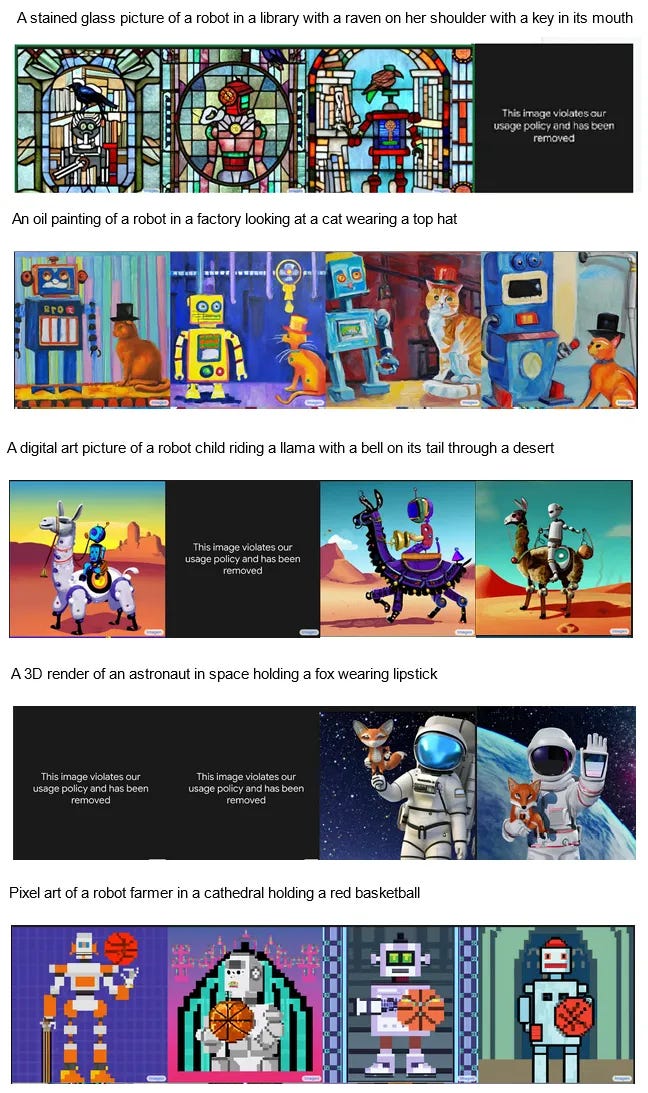
I said it got the cat, llama, and basketball exactly right, meeting the necessary 3/5. Edwin and his evaluators disagreed. They granted success on the cat. But the llama didn’t really have a clear bell on its tail (the closest, #4, was more of a globe). And the final robot wasn’t much of a farmer, wasn’t in much of a cathedral, and the basketball was more orange than red. They granted me 1/5. Fine.
Image Set 3: January 2024
One of the questions on the 2023 - 2024 ACX prediction contest was whether any AI would win the bet by the end of 2023. In order to resolve the question, Edwin and his Surge team returned to the image mines in January 2024. They checked DALL-E3 and Midjourney; I’m including only the pictures from DALL-E3, which did better. Here they are:


These are of higher artistic quality, and they can finally generate humans (instead of just robots).
But they still don’t win the bet. This time Edwin granted the cat and the farmer. But the stupid llama still didn’t have the bell on its tail, the #$%&ing raven still didn’t have the key in its mouth, and although the fox had lipstick in one picture (#2), the astronaut wasn’t exactly holding it. 2/5, one short of victory.
On prediction markets, where users had given 62% probability that Edwin would grant me the win that year, reactions were outraged. “Are you kidding me?” asked one commenter. “Is Edwin Chen an asshole? Clearly he is,” said another.
Image Set 4: September - December 2024
User askwho on the Bayesian Conspiracy Discord claimed that Google Imagen passed the test in September 2024 (he said Imagen 2, but based on the timing it may have been Imagen 3). But he didn’t post it publicly and couldn’t remember all details, so I’ll evaluate this related claim, also about Imagen 3, from December:





I would give this 3/5. We keep the top-hatted cat and the basketball-holding farmer, and the bell is finally on the llama’s tail. But the raven picture isn’t stained glass, and the fox still doesn’t have lipstick.
I tried to contact Edwin for confirmation, without success. I wondered what had happened to him, and a quick search found that his AI data-labeling company did very well and he’s now probably a billionaire. I hope he’s relaxing on a yacht somewhere, far away from angry prediction market commenters.
In the absence of a grader, I figured I would let the bet run out the clock.
Image Set 5: May - June 2025
These are using ChatGPT 4o, released in May 2025, all images generated June 1 (thanks a reader):





Not only is this 5/5, but it’s an obvious step up in matching the styles, and these were all produced on the first try. In retrospect, it feels like judges were right to dismiss former models, which were sort of blundering about and getting some of them right by coincidence. 4o just works.
Edwin is presumably still on his yacht, but original contest judge Gwern gave it his seal of approval, saying:
I think I agree he has clearly won the bet. As you say, the images look correct and I'm willing to call the ball 'red' because of the overall yellow tint (good old color constancy).
In Memoriam: Your Last Set Of Goalposts, Gone But Not Forgotten
It’s probably bad form to write a whole blog post gloating that you won a bet.
I’m doing it anyway, because we’re still having the same debate - whether AI is a “stochastic parrot” that will never be able to go beyond “mere pattern-matching” into the realm of “real understanding”.
My position has always been that there’s no fundamental difference: you just move from matching shallow patterns to deeper patterns, and when the patterns are as deep as the ones humans can match, we call that “real understanding”. This isn’t quite right - there’s a certain form of mental agency that humans still do much better than AIs - but again, it’s a (large) difference in degree rather than in kind.
I think this thesis has done well so far. So far, every time people have claimed there’s something an AI can never do without “real understanding”, the AI has accomplished it with better pattern-matching. This was true back in 2020 when GPT-2 failed to add 2+1 and Gary Marcus declared that scaling had failed and it was time to “consider investing in different approaches” (according to Terence Tao, working with AIs is now “on par with trying to advise a mediocre, but not completely incompetent, static simulation of a graduate student”). I think progress in AI art tells the same story.
There is still one discordant note in this story. When I give 4o a really hard prompt…
Please draw a picture of a fox wearing lipstick, holding a red basketball under his arm, reading a newspaper whose headline is "I WON MY THREE YEAR AI BET". The fox has a raven on his shoulder, and the raven has a key in its mouth.
…it still can’t get it quite right:

But a smart human can complete an arbitrarily complicated prompt. So is there still some sense in which the AI is “just pattern matching”, but the human is “really understanding”? Maybe AIs get better at pattern-matching as they scale up, and eventually they’ll get good enough for every conceivable reasonably task, but they still won’t be infinitely good in the same way humans are?
I think there’s something going on here where the AI is doing the equivalent of a human trying to keep a prompt in working memory after hearing it once - something we can’t do arbitrarily well. I admit I can’t prove this, and it’s not necessarily intuitive - the AI does have a scratchpad, not to mention it has the prompt in front of it the whole time. It’s just what makes sense to me based on an analogy with math problems, where AIs often break down at the same point humans do (eg they can multiply two-digit numbers “in their head”, but not three-digit numbers). I think this will be solved when we solve agency well enough that the AI can generate plans like drawing part of the picture at a time, then checking the prompt, then doing the rest of it. This may require new skills, like self-reference and planning, which might be added in by hand, emerge naturally from the scaling and training process, or some combination of both.


If you disagree, let me know - maybe we can bet on it!
Thanks to everyone who helped operationalize, judge, and generate images for this bet. Vitor, you owe me $100, email me at scott@slatestarcodex.com.