
God Help Us, Let's Try To Understand AI Monosemanticity
Inside every AI is a bigger AI, trying to get out

You’ve probably heard AI is a “black box”. No one knows how it works. Researchers simulate a weird type of pseudo-neural-tissue, “reward” it a little every time it becomes a little more like the AI they want, and eventually it becomes the AI they want. But God only knows what goes on inside of it.
This is bad for safety. For safety, it would be nice to look inside the AI and see whether it’s executing an algorithm like “do the thing” or more like “trick the humans into thinking I’m doing the thing”. But we can’t. Because we can’t look inside an AI at all.
Until now! Towards Monosemanticity, recently out of big AI company/research lab Anthropic, claims to have gazed inside an AI and seen its soul. It looks like this:
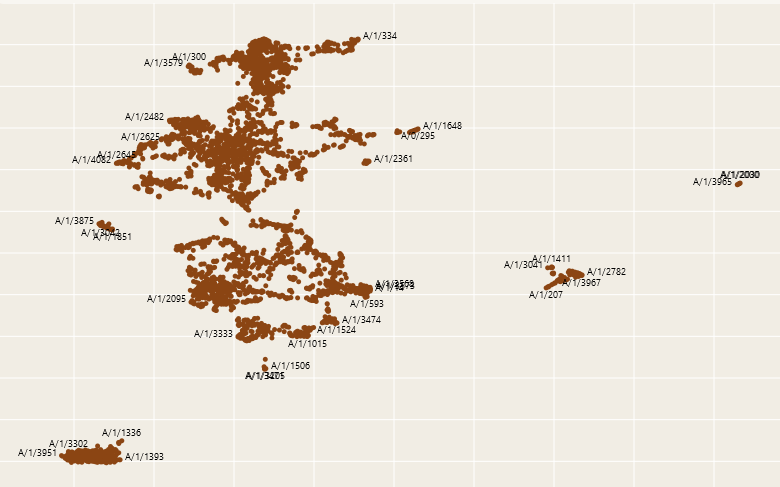
How did they do it? What is inside of an AI? And what the heck is “monosemanticity”?
[disclaimer: after talking to many people much smarter than me, I might, just barely, sort of understand this. Any mistakes below are my own.]
Inside Every AI Is A Bigger AI, Trying To Get Out
A stylized neural net looks like this:
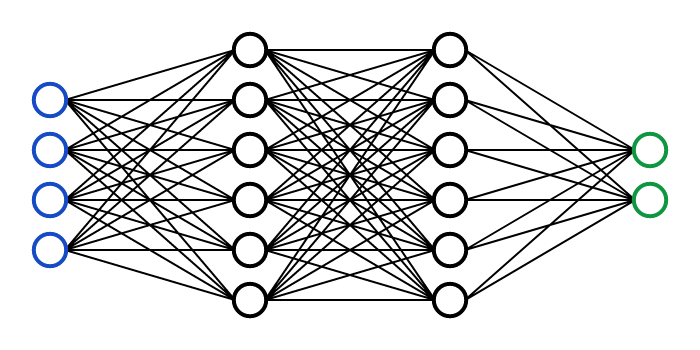
Input neurons (blue) take information from the world. In an image AI, they might take the values of pixels in the image; in a language AI, they might take characters in a text.
These connect to interneurons (black) in the “hidden layers”, which do mysterious things.
Then those connect to output neurons (green). In an image AI, they might represent values of pixels in a piece of AI art; in a language AI, characters in the chatbot response.
“Understanding what goes on inside an AI” means understanding what the black neurons in the middle layer do.
A promising starting point might be to present the AI with lots of different stimuli, then see when each neuron does vs. doesn’t fire. For example, if there’s one neuron that fires every time the input involves a dog, and never fires any other time, probably that neuron is representing the concept “dog”.
Sounds easy, right? A good summer project for an intern, right?
There are at least two problems.
First, GPT-4 has thousands or tens of thousands of neurons (the exact number seems to be secret, but it’s somewhere up there).
Second, this doesn’t work. When you switch to a weaker AI with “only” a few hundred neurons and build special tools to automate the stimulus/analysis process, the neurons aren’t this simple. A few low-level ones respond to basic features (like curves in an image). But deep in the middle, where the real thought has to be happening, there’s nothing representing “dog”. Instead, the neurons are much weirder than this. In one image model, an earlier paper found “one neuron that responds to cat faces, fronts of cars, and cat legs”. The authors described this as “polysemanticity” - multiple meanings for one neuron.

Some very smart people spent a lot of time trying to figure out what conceptual system could make neurons behave like this, and came up with the Toy Models Of Superposition paper.
Their insight is: suppose your neural net has 1,000 neurons. If each neuron represented one concept, like “dog”, then the net could, at best, understand 1,000 concepts. Realistically it would understand many fewer than this, because in order to get dogs right, it would need to have many subconcepts like “dog’s face” or “that one unusual-looking dog”. So it would be helpful if you could use 1,000 neurons to represent much more than 1,000 concepts.
Here’s a way to make two neurons represent five concepts (adapted from here):

If neuron A is activated at 0.5, and neuron B is activated at 0, you get “dog”.
If neuron A is activated at 1, and neuron B is activated at 0.5, you get “apple”.
And so on.
The exact number of vertices in this abstract shape is a tradeoff. More vertices means that the two-neuron-pair can represent more concepts. But it also risks confusion. If you activate the concepts “dog” and “heart” at the same time, the AI might interpret this as “apple”. And there’s some weak sense in which the AI interprets “dog” as “negative eye”.
This theory is called “superposition”. Do AIs really do it? And how many vertices do they have on their abstract shapes?
The Anthropic interpretability team trained a very small, simple AI. It needed to remember 400 features, but it had only 30 neurons, so it would have to try something like the superposition strategy. Here’s what they found (slightly edited from here):
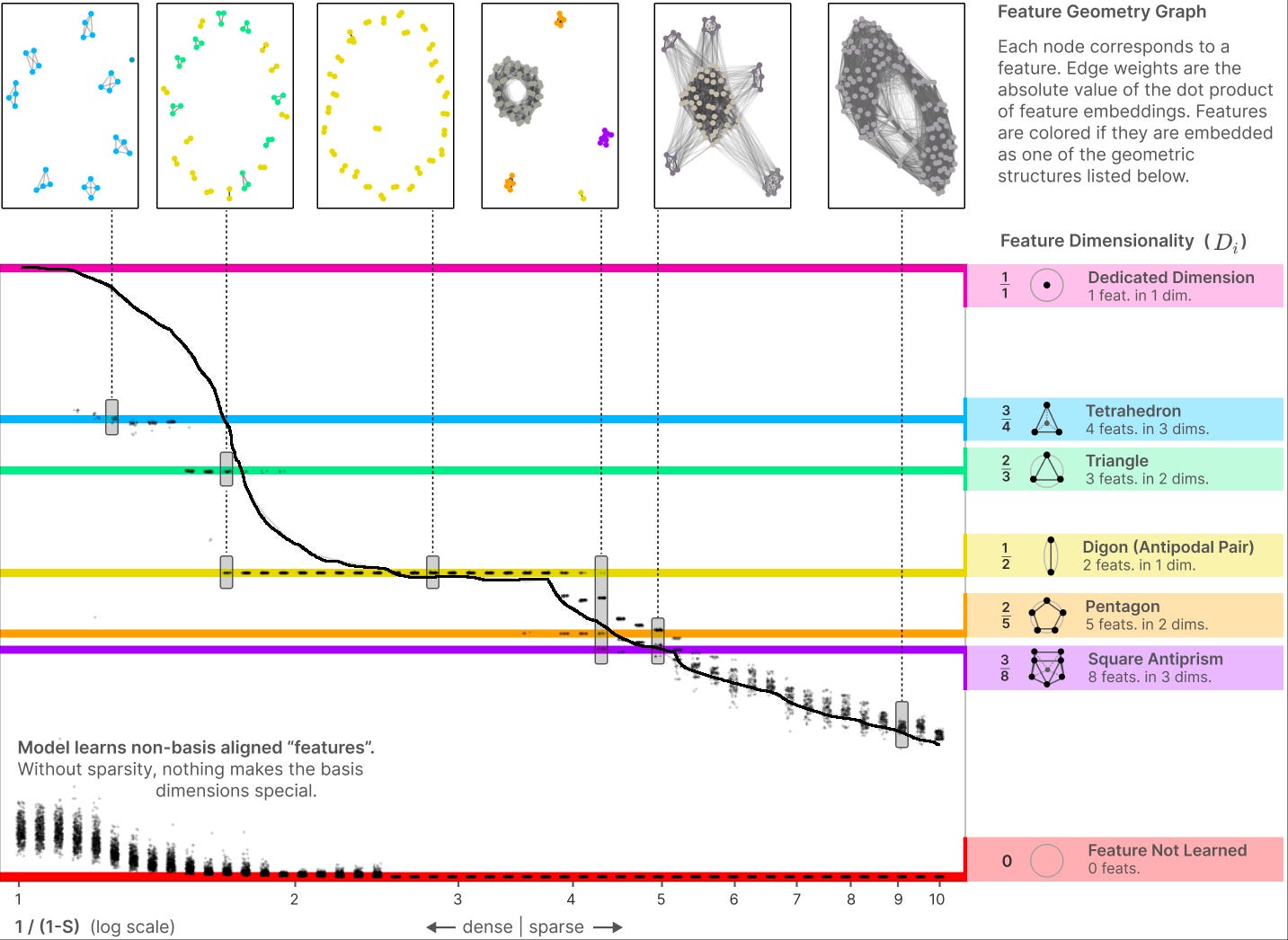
Follow the black line. On the far left of the graph, the data is dense; you need to think about every feature at the same time. Here the AI assigns one neuron per concept (meaning it will only ever learn 30 of the 400 concepts it needs to know, and mostly fail the task).
Moving to the right, we allow features to be less common - the AI may only have to think about a few at a time. The AI gradually shifts to packing its concepts into tetrahedra (three neurons per four concepts) and triangles (two neurons per three concepts). When it reaches digons (one neuron per two concepts) it stops for a while (to repackage everything this way?) Next it goes through pentagons and an unusual polyhedron called the “square anti-prism” . . .

. . . which Wikipedia says is best known for being the shape of the biscornu (a “stuffed ornamental pincushion”) and One World Trade Center in New York:

After exhausting square anti-prisms (8 features per three neurons) it gives up. Why? I don’t know.
A friend who understands these issues better than I warns that we shouldn’t expect to find pentagons and square anti-prisms in GPT-4. Probably GPT-4 does something incomprehensible in 1000-dimensional space. But it’s the 1000-dimensional equivalent of these pentagons and square anti-prisms, conserving neurons by turning them into dimensions and then placing concepts in the implied space.
The Anthropic interpretability team describes this as simulating a more powerful AI. That is, the two-neuron AI in the pentagonal toy example above is simulating a five-neuron AI. They go on to prove that the real AI can then run computations in the simulated AI; in some sense, there really is an abstract five neuron AI doing all the cognition. The only reason all of our AIs aren’t simulating infinitely powerful AIs and letting them do all the work is that as real neurons start representing more and more simulated neurons, it produces more and more noise and conceptual interference.
This is great for AIs but bad for interpreters. We hoped we could figure out what our AIs were doing just by looking at them. But it turns out they’re simulating much bigger and more complicated AIs, and if we want to know what’s going on, we have to look at those. But those AIs only exist in simulated abstract hyperdimensional spaces. Sounds hard to dissect!
God From The Machine
Still, last month Anthropic’s interpretability team announced that they successfully dissected of one of the simulated AIs in its abstract hyperdimensional space.
(finally, we’re back to the monosemanticity paper!)
First the researchers trained a very simple 512-neuron AI to predict text, like a tiny version of GPT or Anthropic’s competing model Claude.
Then, they trained a second AI called an autoencoder to predict the activations of the first AI. They told it to posit a certain number of features (the experiments varied between ~2,000 and ~100,000), corresponding to the neurons of the higher-dimensional AI it was simulating. Then they made it predict how those features mapped onto the real neurons of the real AI.
They found that even though the original AI’s neurons weren’t comprehensible, the new AI’s simulated neurons (aka “features”) were! They were monosemantic, ie they meant one specific thing.
Here’s feature #2663 (remember, the original AI only had 512 neurons, but they’re treating it as simulating a larger AI with up to ~100,000 neuron-features).
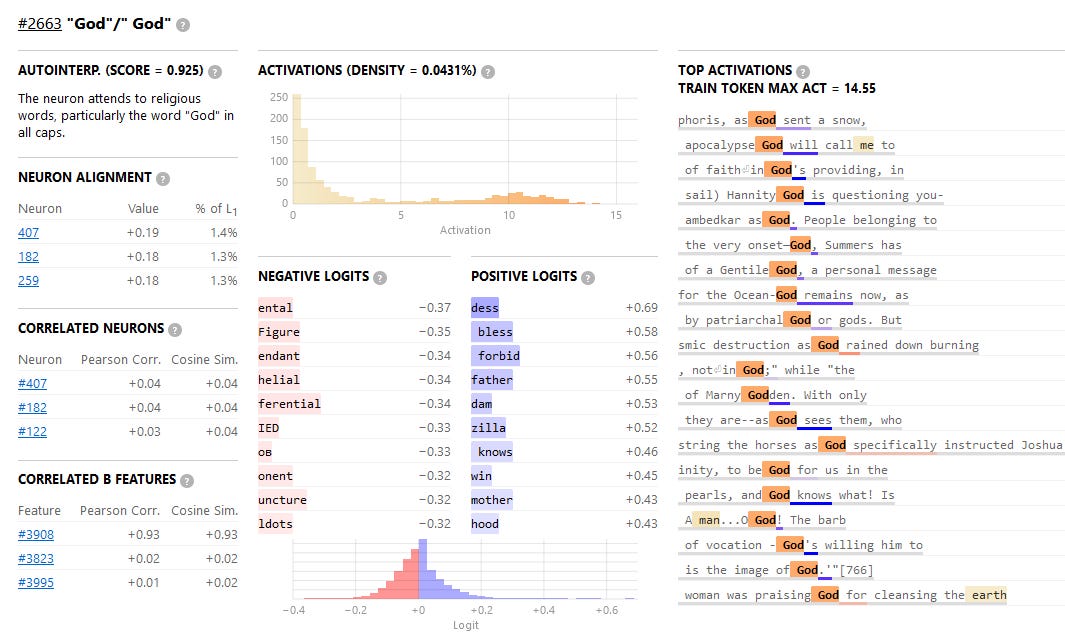
Feature #2663 represents God.
The single sentence in the training data that activated it most strongly is from Josephus, Book 14: “And he passed on to Sepphoris, as God sent a snow”. But we see that all the top activations are different uses of “God”.
This simulated neuron seems to be composed of a collection of real neurons including 407, 182, and 259, though probably there are many more than these and the interface just isn’t showing them to me.
None of these neurons are themselves very Godly. When we look at neuron #407 - the real neuron that contributes most to the AI’s understanding of God! - an AI-generated summary describes it as “fir[ing] primarily on non-English text, particularly accented Latin characters. It also occasionally fires on non-standard text like HTML tags.” Probably this is because you can’t really understand AIs at the real-neuron-by-real-neuron level, so the summarizing AI - having been asked to do this impossible thing - is reading tea leaves and saying random stuff.
But at the feature level, everything is nice and tidy! Remember, this AI is trying to predict the next token in a text. At this level, it does so intelligibly. When Feature #2663 is activated, it increases the probability of the next token being “bless”, “forbid”, “damn”, or “-zilla”.
Shouldn’t the AI be keeping the concept of God, Almighty Creator and Lord of the Universe, separate from God- as in the first half of Godzilla? Probably GPT-4 does that, but this toy AI doesn’t have enough real neurons to have enough simulated neurons / features to spare for the purpose. In fact, you can see this sort of thing change later in the paper:
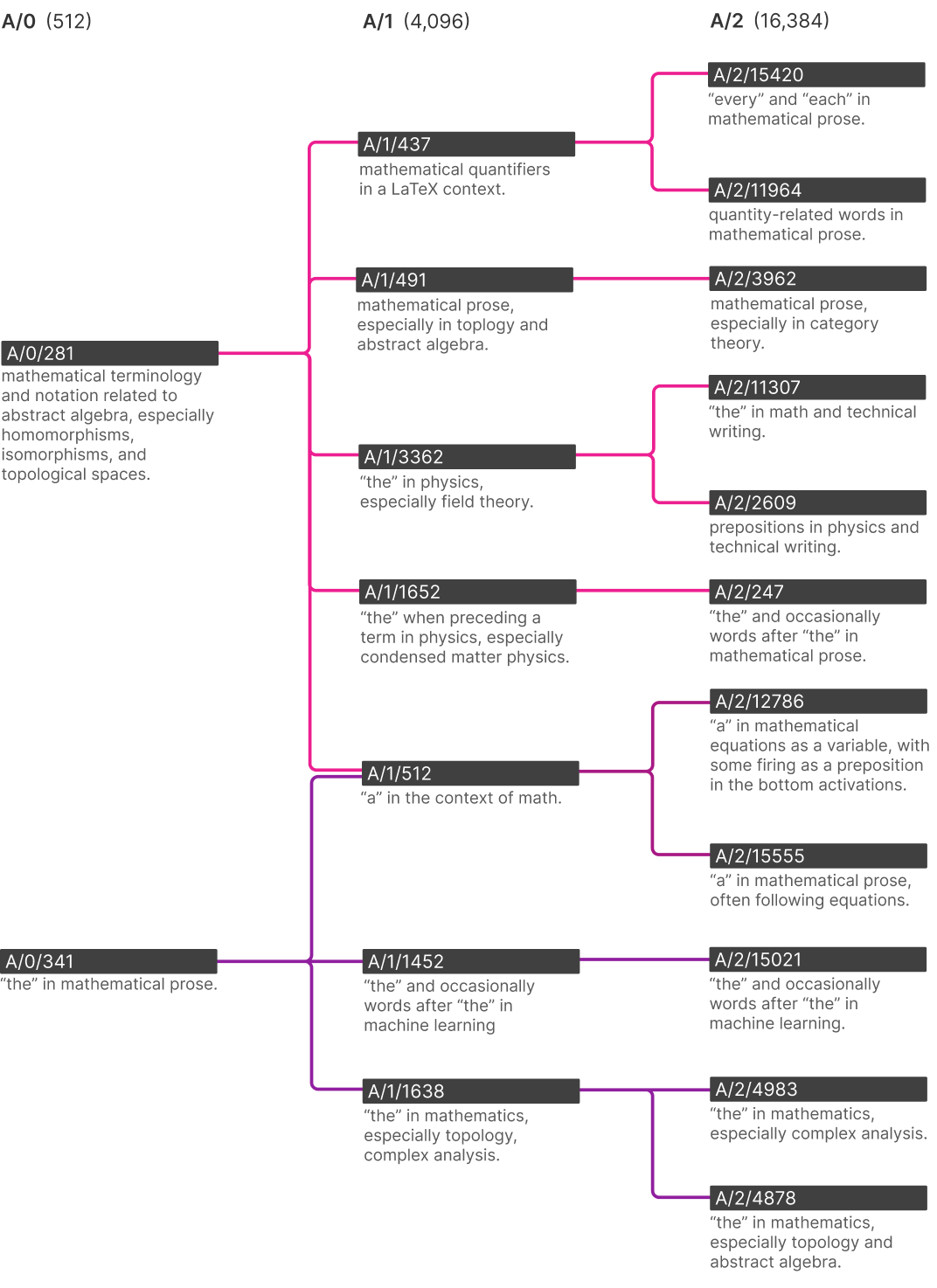
At the bottom of this tree, you can see what happens to the AI’s representation of “the” in mathematical terminology as you let it have more and more features.
First: why is there a feature for “the” in mathematical terminology? I think because of the AI’s predictive imperative - it’s helpful to know that some specific instance of “the” should be followed by math words like “numerator” or “cosine”.
In their smallest AI (512 features), there is only one neuron for “the” in math. In their largest AI tested here (16,384 features), this has branched out to one neuron for “the” in machine learning, one for “the” in complex analysis, and one for “the” in topology and abstract algebra.
So probably if we upgraded to an AI with more simulated neurons, the God neuron would split in two - one for God as used in religions, one for God as used in kaiju names. Later we might get God in Christianity, God in Judaism, God in philosophy, et cetera.
Not all features/simulated-neurons are this simple. But many are. The team graded 412 real neurons vs. simulated neurons on subjective interpretability, and found the simulated neurons were on average pretty interpretable:
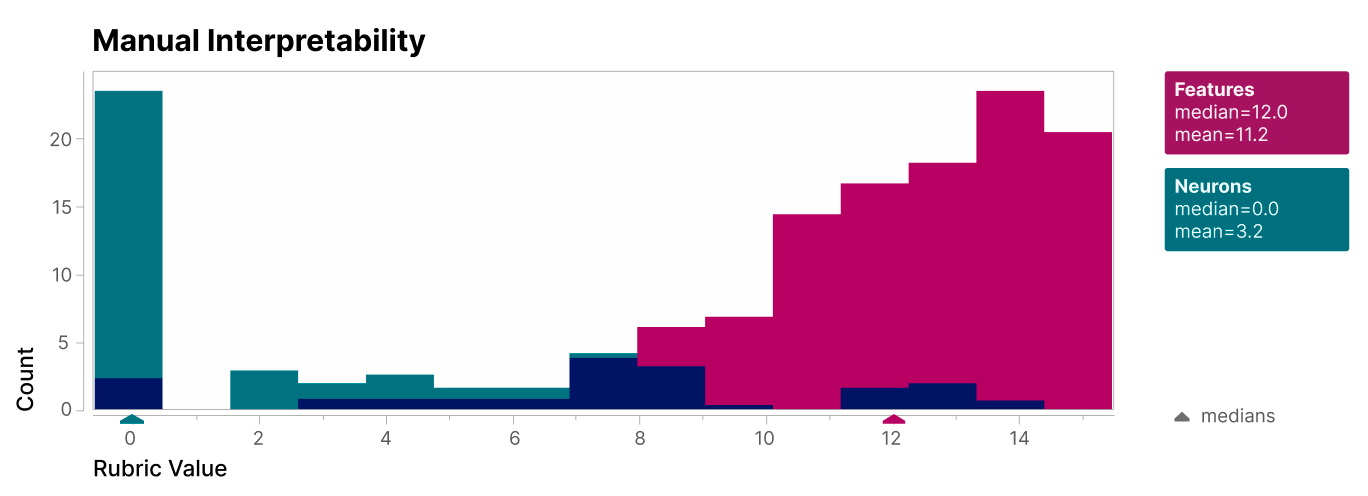
Some, like the God neuron, are for specific concepts. Many others, including some of the most interpretable, are for “formal genres” of text, like whether it’s uppercase or lowercase, English vs. some other alphabet, etc.
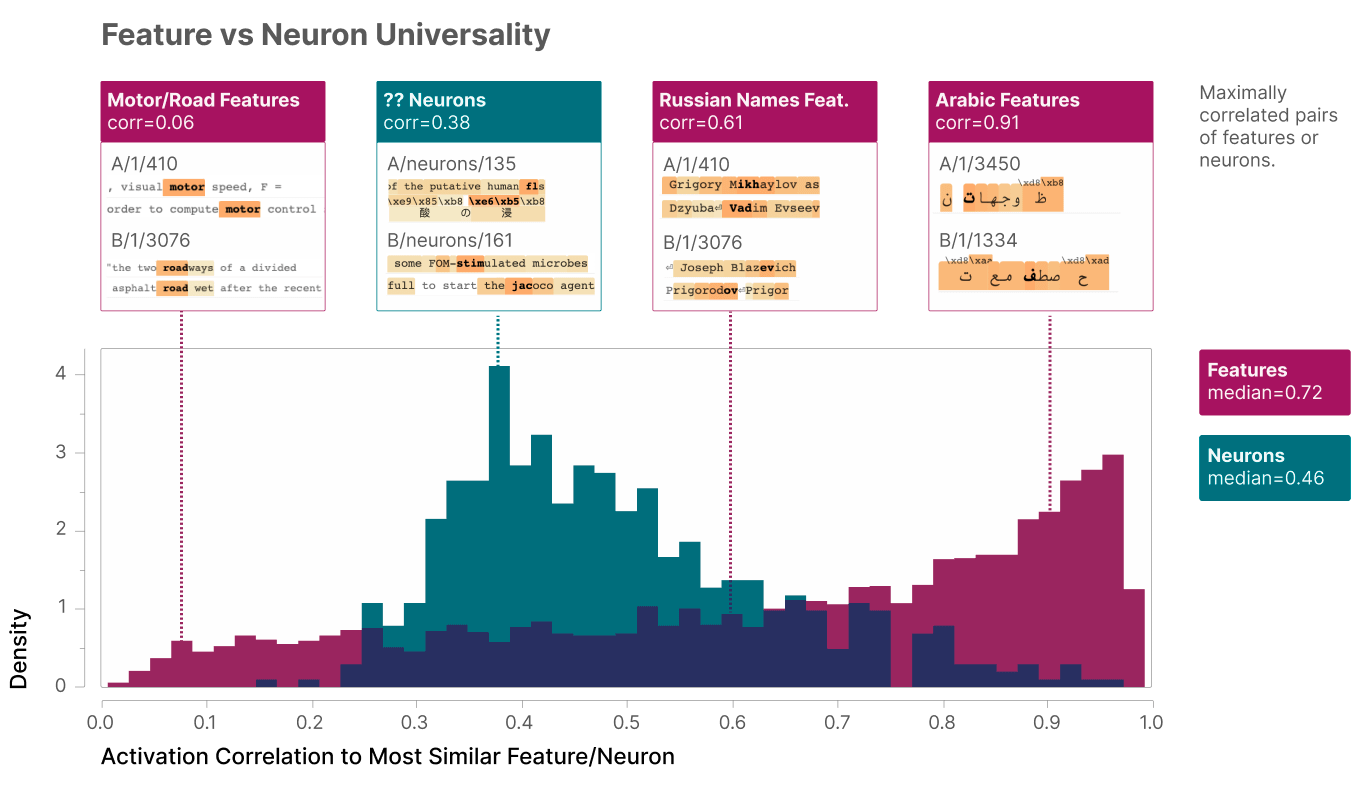
How common are these features? That is, suppose you train two different 4,096-feature AIs on the same text datasets. Will they have mostly the same 4,096 features? Will they both have some feature representing God? Or will the first choose to represent God together with Godzilla, and the second choose to separate them? Will the second one maybe not have a feature for God at all, instead using that space to store some other concept the first AI can’t possibly understand?
The team tests this, and finds that their two AIs are pretty similar! On average, if there’s a feature in the first one, the most similar feature in the second one will “have a median correlation of 0.72”.
I Have Seen The Soul Of The AI, And It Is Good
What comes after this?
In May of this year, OpenAI tried to make GPT-4 (very big) understand GPT-2 (very small). They got GPT-4 to inspect each of GPT-2’s 307,200 neurons and report back on what it found.
It found a collection of intriguing results and random gibberish, because they hadn’t mastered the techniques described above of projecting the real neurons into simulated neurons and analyzing the simulated neurons instead. Still, it was impressively ambitious. Unlike the toy AI in the monosemanticity paper, GPT-2 is a real (albeit very small and obsolete) AI that once impressed people.
But what we really want is to be able to interpret the current generation of AIs. The Anthropic interpretability team admits we’re not there yet, for a few reasons.
First, scaling the autoencoder:
Scaling the application of sparse autoencoders to frontier models strikes us as one of the most important questions going forward. We're quite hopeful that these or similar methods will work – Cunningham et al.'s work seems to suggest this approach can work on somewhat larger models, and we have preliminary results that point in the same direction. However, there are significant computational challenges to be overcome. Consider an autoencoder with a 100× expansion factor applied to the activations of a single MLP layer of width 10,000: it would have ~20 billion parameters. Additionally, many of these features are likely quite rare, potentially requiring the autoencoder to be trained on a substantial fraction of the large model's training corpus. So it seems plausible that training the autoencoder could become very expensive, potentially even more expensive than the original model. We remain optimistic, however, and there is a silver lining – it increasingly seems like a large chunk of the mechanistic interpretability agenda will now turn on succeeding at a difficult engineering and scaling problem, which frontier AI labs have significant expertise in.
In other words, in order to even begin to interpret an AI like GPT-4 (or Anthropic’s equivalent, Claude), you would need an interpreter-AI around the same size. But training an AI that size takes a giant company and hundreds of millions (soon billions) of dollars.
Second, scaling the interpretation. Suppose we find all the simulated neurons for God and Godzilla and everything else, and have a giant map of exactly how they connect, and hang that map in our room. Now we want to answer questions like:
If you ask the AI a controversial question, how does it decide how to respond?
Is the AI using racial stereotypes in forming judgments of people?
Is the AI plotting to kill all humans?
There will be some combination of millions of features and connections that answers these questions. In some case we can even imagine how we would begin to do it - check how active the features representing race are when we ask it to judge people, maybe. But realistically, when we’re working with very complex interactions between millions of neurons we’ll have to automate the process, some larger scale version of “ask GPT-4 to tell us what GPT-2 is doing”.
This probably works for racial stereotypes. It’s more complicated once you start asking about killing all humans (what if the GPT-4 equivalent is the one plotting to kill all humans, and feeds us false answers?) But maybe there’s some way to make an interpreter AI which itself is too dumb to plot, but which can interpret a more general, more intelligent, more dangerous AI. You can see more about how this could tie into more general alignment plans in the post on the ELK problem. I also just found this paper, which I haven’t fully read yet but which seems like a start on engineering safety into interpretable AIs.
Finally, what does all of this tell us about humans?
Humans also use neural nets to reason about concepts. We have a lot of neurons, but so does GPT-4. Our data is very sparse - there are lots of concepts (eg octopi) that come up pretty rarely in everyday life. Are our brains full of strange abstract polyhedra? Are we simulating much bigger brains?
This field is very new, but I was able to find one paper, Identifying Interpretable Visual Features in Artificial and Biological Neural Systems. The authors say:
Through a suite of experiments and analyses, we find evidence consistent with the hypothesis that neurons in both deep image model [AIs] and the visual cortex [of the brain] encode features in superposition. That is, we find non-axis aligned directions in the neural state space that are more interpretable than individual neurons. In addition, across both biological and artificial systems, we uncover the intriguing phenomenon of what we call feature synergy - sparse combinations in activation space that yield more interpretable features than the constituent parts. Our work pushes in the direction of automated interpretability research for CNNs, in line with recent efforts for language models. Simultaneously, it provides a new framework for analyzing neural coding properties in biological systems.
This is a single non-peer-reviewed paper announcing a surprising claim in a hype-filled field. That means it has to be true - otherwise it would be unfair!
If this topic interests you, you might want to read the full papers, which are much more comprehensive and interesting than this post was able to capture. My favorites are:
In the unlikely scenario where all of this makes total sense and you feel like you’re ready to make contributions, you might be a good candidate for Anthropic or OpenAI’s alignment teams, both of which are hiring. If you feel like it’s the sort of thing which could make sense and you want to transition into learning more about it, you might be a good candidate for alignment training/scholarship programs like MATS.