
Crowds Are Wise (And One's A Crowd)
The long road to Moscow

The “wisdom of crowds” hypothesis claims that the average of many guesses is better than a single guess. Ask one person to guess how much a cow weighs, and they’ll be off by some amount. Ask a hundred people and take the average of their answers, and you’ll be off by less.
I was intrigued by a claim in this book review that:
You can play “wisdom of crowds” in single-player mode. Say you want to know the weight of a cow. Then take a guess. Now throw your guess out of the window, and take another guess. Finally, compute the average of your two guesses. The claim is that this average is better than your individual guesses.
This is spooky. We talk a lot about how to make accurate predictions here - and you can improve your accuracy on anything just by guessing twice and averaging, no additional knowledge required? It’s like God has handed us a creepy cow-weight oracle.
I wanted to test this myself, so I included some relevant questions in last year’s ACX Survey:
The true answer was 2,486 km. 6,942 people gave answers to both questions. Many of those answers were very wrong - trolls? lizardmen? - so where not otherwise specified, I did all averages with geometric mean - ie sqrt(x * y) instead of (x+y)/2 - which tolerates outliers more gracefully.
How Does Wisdom Vary With Crowd Size?
The average participant was off by 918 km. I’m averaging so many different things in so many different steps here that it gets confusing, but I think what I mean is
geometric_mean[absolute_value($ANSWER - 2487)], for all 6924 answers = 918In accordance with the wisdom of crowds hypothesis, this error decreased to 714 km when I separated the participants into crowds of size two, ie
geometric_mean[absolute_value(geometric_mean<$ANSWERX, $ANSWERY> - 2487)], for 6924 randomly selected pairings of ANSWERX, ANSWERY = 714Here’s how error varied with crowd size:
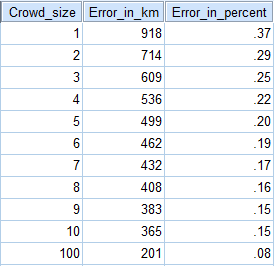
What about larger crowds? I found that the crowd of all respondents, ie a 6924 person crowd, got higher error than the 100 person crowd (243 km). This doesn’t seem right to me, but I think the explanation is something like: I tested 60 different 100 person crowds and took their average. Some of the 60 different 100 person crowds were better-than-average, and some were worse-than-average, but because there were many of them, it averaged out to an average, which should be close to the “true value” of how wisdom-of-crowds scales. But I only had one 6924 person crowd, ie the entire survey, and it so happened that that crowd did worse than average for a crowd of that size. Since we only have one datapoint for the n = 6924 crowd size, it’s not significant and we should throw it out.
Here’s a graph (missing the n=100 point so it can be nice and to scale):

This looks like some specific elegant curve, but which one? A real statistician would be able to give a good answer to this question. I can’t, but after mashing some buttons on my statistics program and seeing what happened, I got the equation
-Epistemic status: Wild speculation outside the limits of my competence-
1/ERROR = 2.34 + [1.8 * ln(CROWD_SIZE)]…which does okay at predicting the n=100 data point too. This equation implies that as crowd size approaches infinity, error approaches zero (albeit very slowly). But I included that assumption when choosing the equation - I didn’t test it. You can also imagine that there’s some consistent bias. For example, if the most commonly used map projection is distorted such that eyeballing the distance on a map perfectly would leave you off by 100 km, an infinitely-sized crowd might converge to an error of 100 km. I can’t tell if that’s going on here or not.
For what it’s worth, taking the equation seriously suggests that if all 8 billion people on Earth took my survey, we would have gotten within 50 km of the true distance.
Nick Bostrom speculates that in the far future, a multigalactic supercivilization might be able to support 10^46 simulated humans per century. If all of them took my survey, we could get within 12 km.
Can You Really Do Wisdom Of Crowds With Yourself?
As mentioned above, the average respondent was off by 918 km on their first guess.
They were off by 967 km on their second guess.
And on the average of their guesses, they were off by . . . it depends if you mean arithmetic or geometric average. The arithmetic average was better, 916 km. The geometric average was worse, 940 km.
Arithmetic average is more commonly used. But I’d been using geometric average before, to deal with outliers. But this is a simple averaging of two quantities, where “outlier” is meaningless. So maybe arithmetic mean is more appropriate again?
If we remove all ridiculous outliers from the data (anything above 40000 km, which would get you all the way around the Earth, or below 200 km, which wouldn’t even get you out of France) the picture is similar. Error on the first guess goes down to 858 km, on the second to 898 km, on the geometric mean to 873 km, and on the arithmetic mean to 845 km. Now all differences are significant at p < 0.001.
Notice that two guesses from the same person were much less effective than two guesses from two different people, bringing the error down by 2 - 13 km instead of 200.
This analysis is limited by having only one question, meaning that I can’t test whether the choices I made were good vs. p-hacking. If I had another question like this, I would like to confirm that removing outliers and using arithmetic instead of geometric mean for the stage where you average the two guesses still produces better results. At this point I can just say that I’ve found suggestive evidence that the wisdom-of-crowds-with-yourself hypothesis holds.
Is the bound as number of guesses goes to infinity still zero? Can you get any question right just by guessing thousands of times, then averaging the results? Surely the answer has to be “no” - otherwise it would be too OP.
Van Dolder, Van Den Assem
Van Dolder and Van Den Assem did a much bigger wisdom-of-inner-crowds experiment, published here in Nature Human Behavior. It answers the “infinite inner crowd” question and tells us more about how the phenomenon works.
VD and VDA got data from a Dutch casino that had a “guess the number of objects in a glass container” contest each year for several years (the real number was usually in the tens of thousands). Several hundred thousand people played, some more than once. Here are their results:
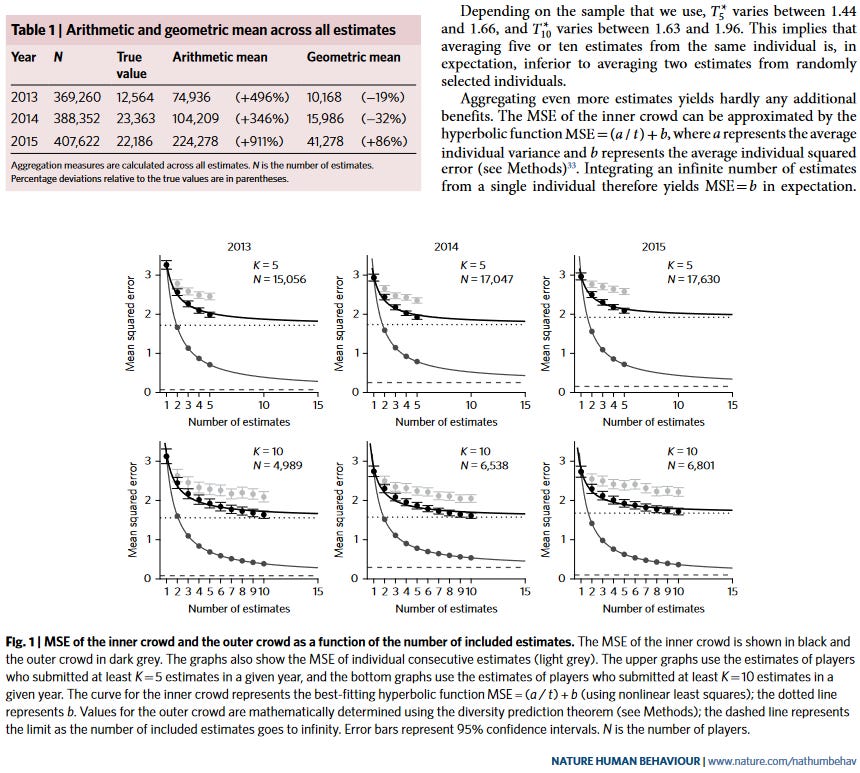
If I’m reading this right, they find:
Both inner and outer (ie real) crowds get more accurate as crowd size increases.
Outer crowds are much more effective than inner crowds. An inner crowd of size infinity performs about as well as an outer crowd of size two.
You can approximately halve outer crowd error (in this task) by going from one to two people (this wasn’t true in my Moscow task!). About 90% of outer crowd error can be removed by going from one to ten people; going from ten to infinity people only removes an additional 10%.
The best fit is with a hyperbolic function
Outer crowds seem to approach approximately zero error as crowd size equals infinity. Inner crowds seem to approach some finite error equal to (in this task!) about half the error of their first estimate.
They also find that . . .
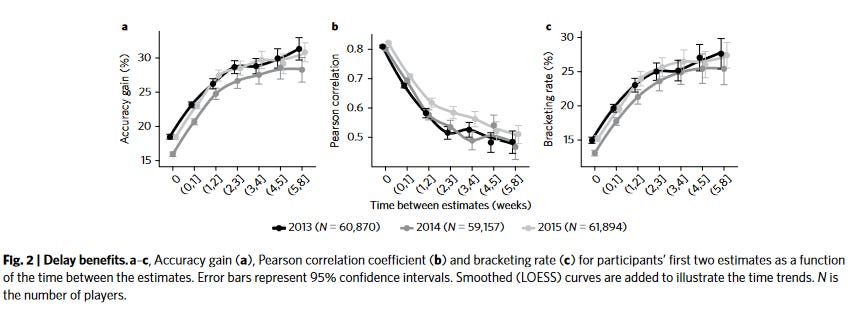
. . . the longer someone waits between making two guesses, the less correlated their guesses are, and the more inner-crowd-wisdom-effect they gain from averaging those guesses.
Is It Weird That Nobody Thinks About This?
Is wisdom of crowds already too OP?
How much you’ll make at various different career options is an estimate. So is how much you’ll like your job. So is the percent chance that you’ll meet your soulmate if you go to some specific party. So is the number of people who would die if your country declared war on its arch-enemy. So is the percent chance that your country would win. If you could cut your error rate by 2/3 by using wisdom of crowds techniques with a crowd of ten, isn’t that really valuable?
I think the answer is something like: you can only use wisdom of crowds on numerical estimates, very few people (currently) make those decisions numerically, and the cost of making those decisions numerically is higher (for most people) than the benefit of using wisdom of crowds on them.
That is, most people don’t decide to go into academia rather than industry because they estimate their happiness would be 8/10 on a ten point scale in academia but only 5/10 on a ten point scale in industry. They just feel vaguely more positive about academia than industry. They could try converting their vague positive feelings into numbers, but they have no practice doing this and would probably mess it up. Even if they could find ten friends who understood the situation, those friends would know less about their preferences than they did and provide worse estimates. Although wisdom of crowds would add back some accuracy, it probably wouldn’t be as much accuracy as those other mistakes cost.
What about in finance, where people often make numerical estimates (eg what a stock will be worth a year from now)? Maybe they have advanced models calculating that, and averaging their advanced models with worse models or people’s vague impressions would be worse than just trusting their most advanced model, in a way that’s not true of an individual trusting their first best guess?
Last month, we found that wisdom of crowds works in forecasting: the aggregate of 500 forecasters scored better than 84% of individuals; the aggregate of superforecasters scored better than individual superforecasters. This is close to a real-world example of wisdom of crowds working - but it won’t be all the way there until people use forecasting in the real world. The crowd did a better job predicting whether Russia would invade Ukraine than individual forecasters did, and I can imagine presidents and generals finding this useful - but mostly they have yet to bite.
As always, you can try to replicate my work using the publicly available ACX Survey Results. If you get slightly different answers than I did, it’s because I’m using the full dataset which includes a few people who didn’t want their answers publicly released. If you get very different answers than I did, it’s because I made a mistake, and you should tell me.